With the explosion of Claude Code, developers are struggling with handle the credit limits. I have seen plenty of Reddit posts complaining about the limitations imposed by the Claude Max plan, even though it costs a whopping $200!
I access Anthropic’s models using the Poe API service, which also gives me access to models by the other major players in the field. In my experience with CC so far, I can easily burn a few percent of the monthly credits in a few minutes of use in a complex codebase—even if you stick with Sonnet, Anthropic’s mid-tier clippy. I can totally see my monthly API credit (about $30) vanishing within one or two days of intense CC sessions in a complex scientific codebase.
I am not spending a couple hundred dollars on clippies, so I have been exploring alternative ways of doing agentic coding and alternative providers. In my explorations, I found opencode: another fantastic terminal-based agentic coding interface which gives you access to other models in addition to Claude. 1 More importantly, it gives me access to a locally-hosted LLM (more about that in another post).
In order to see what else is out there in terms of agentic-coding LLMs and rank their cost-benefit, I crawled the major relevant benchmarks out there. I computed the average ranking of major models, including how much they cost. I went through the following benchmarks in no particular order:
Here is the ranking:
| Ranking | Model Name | Average Score | Credit Cost (per 1k) |
|---|---|---|---|
| 1 | opus | 1.00 | 850 |
| 2 | gemini | 2.75 | 370 |
| 3 | gpt | 5.25 | 470 |
| 4 | gpt-pro | 5.50 | 5600 |
| 5 | sonnet | 6.25 | 500 |
| 6 | minimax | 6.67 | 50 |
| 7 | gpt-codex | 10.00 | 340 |
| 8 | gemini-flash | 12.00 | 100 |
| 9 | deepseek-32 | 13.67 | 23 |
| 10 | kimi | 14.00 | 225 |
| 11 | glm | 14.33 | 94 |
| 12 | haiku | 15.00 | 170 |
| 13 | devstral-small | 24.50 | 1 |
| 14 | gpt-instant | 26.67 | 470 |
| 15 | qwen3-80b | 28.33 | 300 |
| 16 | grok-fast | 31.00 | 20 |
| 17 | grok | 31.50 | 600 |
| 18 | qwen3-coder-30b | 32.67 | 50 |
| 19 | devstral2 | 72.00* | N/A |
| 20 | mistral | 79.00* | 400 |
| 21 | llama-maverick | 80.00* | 55 |
| 22 | qwen3-235b | 88.00* | N/A |
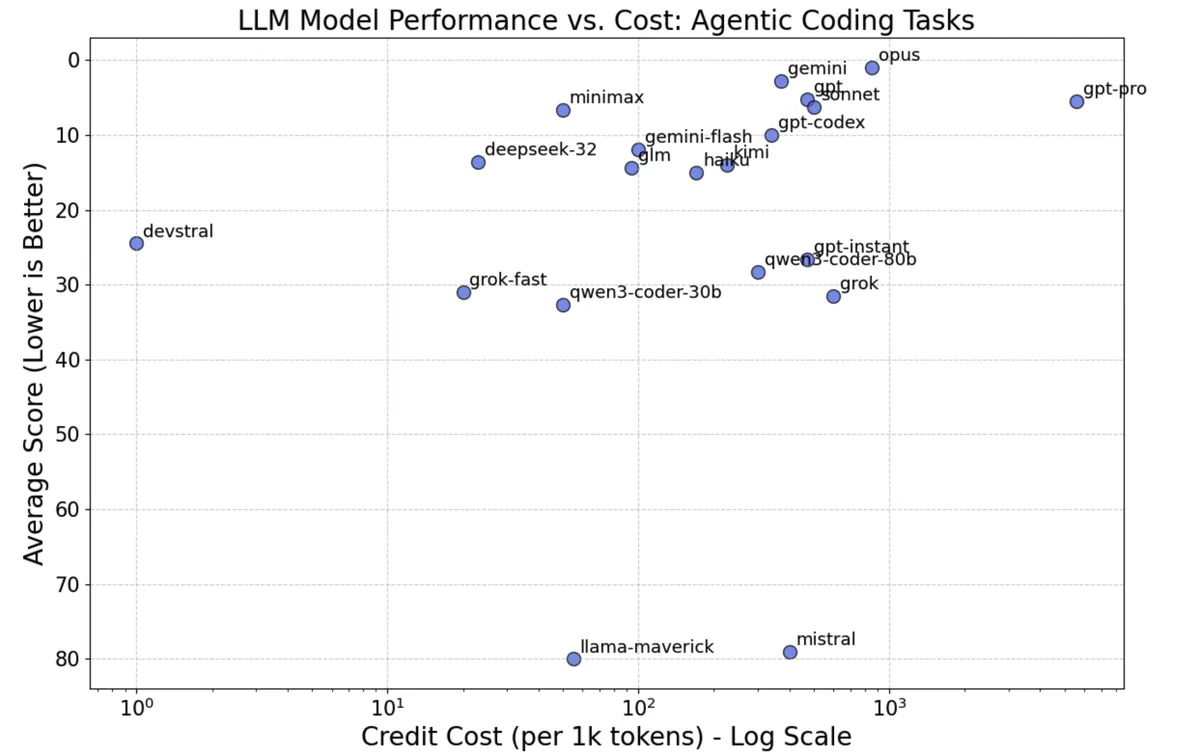
Table showing the LLM ranking for agentic coding. When a model does not include the version, it refers to the latest version available (i.e. gemini means Gemini 3 Pro High, gpt means GPT 5.2 High). Scores with an asterisk include a +50 penalty for incomplete information (only 1 ranking source). Credit cost is the relative cost per 1000 tokens of input and output.
Here is a plot showing the model's score as a function of how much it cost per 1k tokens.
It comes as no surprise that Opus 4.5, Gemini 3 Pro and GPT 5.2 are among the top 3. But notice how open models are getting quite competitive: Minimax M2.1, DeepSeek v3.2 and Kimi K2—all open models which anyone can download—are among the top 10. Also notice how Minimax offers coding performance as good as Sonnet 4.5 but costing 10 times less.
My take from this? Whenever possible I will stick with opencode and Minimax for day-to-day coding tasks. When I need the big guns, I will use CC/Sonnet/Opus.
Recently Anthropic devs enabled CC to talk to other clippies besides Claude. My experience so far with CC 2.1.15 is that it does not work very well and CC crashes as soon as you try to make it talk to a locally-hosted Ollama model.↩